[M1 Mac, Big Sur 11.6.7, clang 13.0.0, NO IDE]
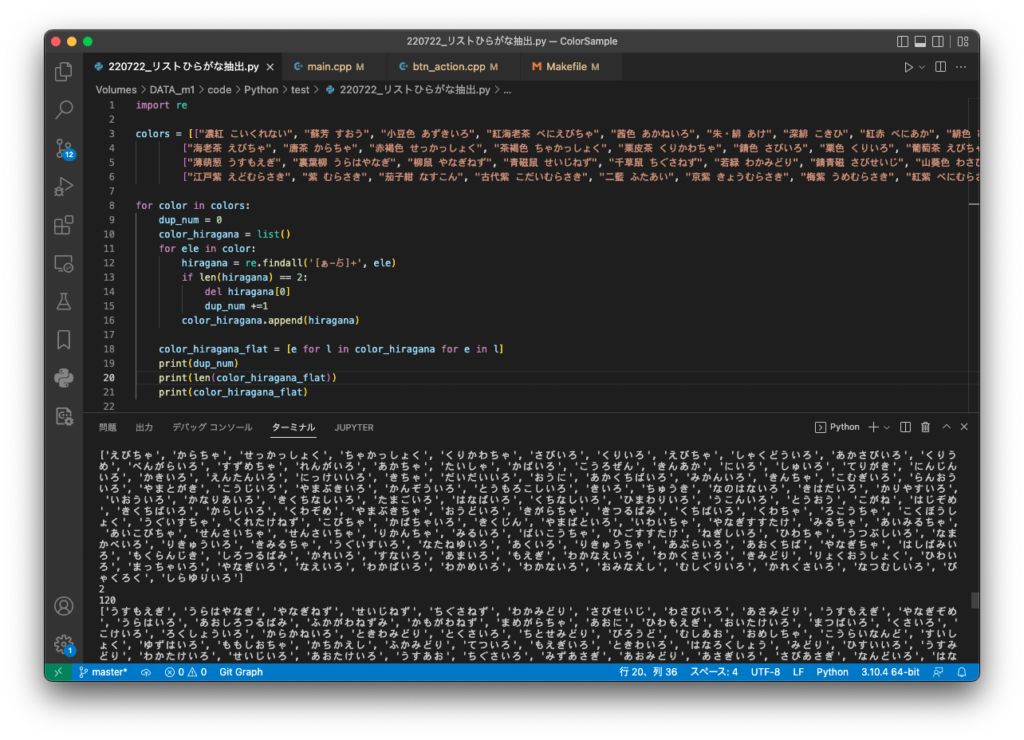
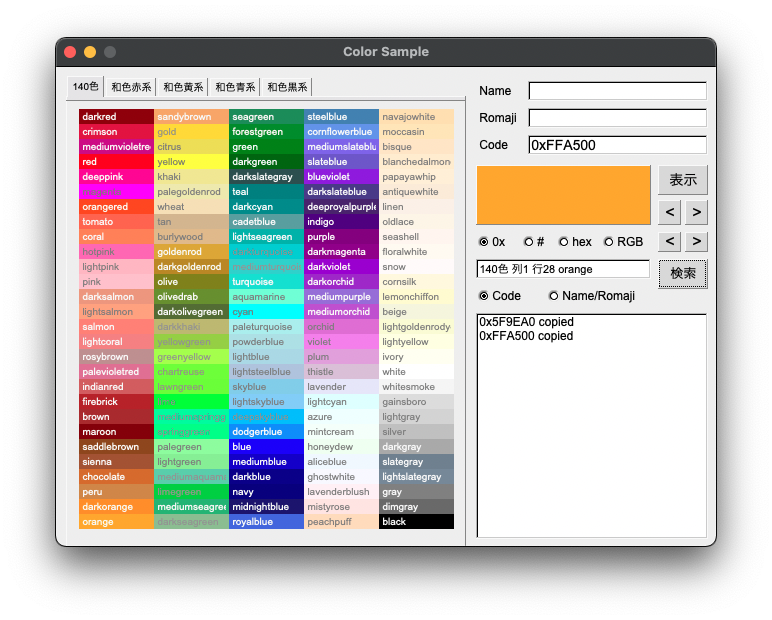
製作中のカラーアプリはCode欄から取得したカラーコードの有無を検索し、ボタンのタブ内位置を表示する機能を搭載していますが、その際にFl_Boxのカラー表示も反映するようにしました。
callback用のshowColor関数を使い回します。引数が異なるのであれば同名の関数設定が可能です。知ってはいましたが初めて使います。もちろん関数の内容が違っていても構いません。
本当はJava(Swing)のdoClickメソッドのようにプログラムから表示ボタンを押させたかったのですが、FLTKドキュメントを隅々まで調べても方法が見つかりませんでした。
// コールバック用
void showColor(Fl_Widget*, void*){
onoff_zero = zero_rbtn->value();
onoff_sharp = sharp_rbtn->value();
onoff_hex = hex_rbtn->value();
onoff_rgb = rgb_rbtn->value();
if (onoff_zero == 1){
ToZeroConvert();
} else if (onoff_sharp == 1){
ToSharpConvert();
} else if (onoff_hex == 1){
ToHexConvert();
} else {
ToRGBConvert();
}
}
// 通常用
void showColor(){
onoff_zero = zero_rbtn->value();
onoff_sharp = sharp_rbtn->value();
onoff_hex = hex_rbtn->value();
onoff_rgb = rgb_rbtn->value();
if (onoff_zero == 1){
ToZeroConvert();
} else if (onoff_sharp == 1){
ToSharpConvert();
} else if (onoff_hex == 1){
ToHexConvert();
} else {
ToRGBConvert();
}
}